VNET (VPP Network Stack)¶
The files associated with the VPP network stack layer are located in the ./src/vnet folder. The Network Stack Layer is basically an instantiation of the code in the other layers. This layer has a vnet library that provides vectorized layer-2 and 3 networking graph nodes, a packet generator, and a packet tracer.
In terms of building a packet processing application, vnet provides a platform-independent subgraph to which one connects a couple of device-driver nodes.
Typical RX connections include “ethernet-input” [full software classification, feeds ipv4-input, ipv6-input, arp-input etc.] and “ipv4-input-no-checksum” [if hardware can classify, perform ipv4 header checksum].
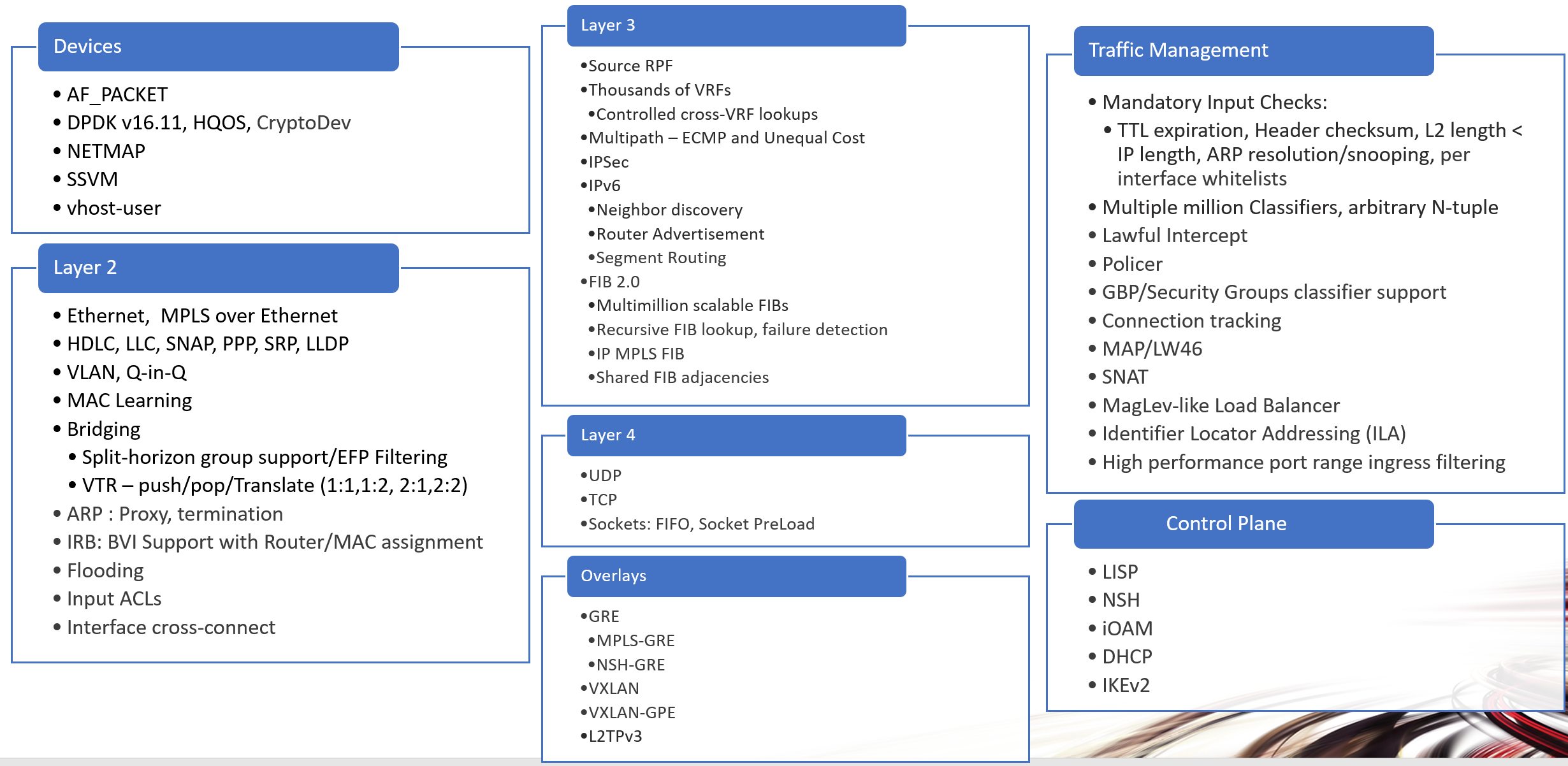
List of features and layer areas that VNET works with:
Effective graph dispatch function coding¶
Over the 15 years, multiple coding styles have emerged: a single/dual/quad loop coding model (with variations) and a fully-pipelined coding model.
Single/dual loops¶
The single/dual/quad loop model variations conveniently solve problems where the number of items to process is not known in advance: typical hardware RX-ring processing. This coding style is also very effective when a given node will not need to cover a complex set of dependent reads.
Here is an quad/single loop which can leverage up-to-avx512 SIMD vector units to convert buffer indices to buffer pointers:
static uword
simulated_ethernet_interface_tx (vlib_main_t * vm,
vlib_node_runtime_t *
node, vlib_frame_t * frame)
{
u32 n_left_from, *from;
u32 next_index = 0;
u32 n_bytes;
u32 thread_index = vm->thread_index;
vnet_main_t *vnm = vnet_get_main ();
vnet_interface_main_t *im = &vnm->interface_main;
vlib_buffer_t *bufs[VLIB_FRAME_SIZE], **b;
u16 nexts[VLIB_FRAME_SIZE], *next;
n_left_from = frame->n_vectors;
from = vlib_frame_args (frame);
/*
* Convert up to VLIB_FRAME_SIZE indices in "from" to
* buffer pointers in bufs[]
*/
vlib_get_buffers (vm, from, bufs, n_left_from);
b = bufs;
next = nexts;
/*
* While we have at least 4 vector elements (pkts) to process..
*/
while (n_left_from >= 4)
{
/* Prefetch next quad-loop iteration. */
if (PREDICT_TRUE (n_left_from >= 8))
{
vlib_prefetch_buffer_header (b[4], STORE);
vlib_prefetch_buffer_header (b[5], STORE);
vlib_prefetch_buffer_header (b[6], STORE);
vlib_prefetch_buffer_header (b[7], STORE);
}
/*
* $$$ Process 4x packets right here...
* set next[0..3] to send the packets where they need to go
*/
do_something_to (b[0]);
do_something_to (b[1]);
do_something_to (b[2]);
do_something_to (b[3]);
/* Process the next 0..4 packets */
b += 4;
next += 4;
n_left_from -= 4;
}
/*
* Clean up 0...3 remaining packets at the end of the incoming frame
*/
while (n_left_from > 0)
{
/*
* $$$ Process one packet right here...
* set next[0..3] to send the packets where they need to go
*/
do_something_to (b[0]);
/* Process the next packet */
b += 1;
next += 1;
n_left_from -= 1;
}
/*
* Send the packets along their respective next-node graph arcs
* Considerable locality of reference is expected, most if not all
* packets in the inbound vector will traverse the same next-node
* arc
*/
vlib_buffer_enqueue_to_next (vm, node, from, nexts, frame->n_vectors);
return frame->n_vectors;
}
Given a packet processing task to implement, it pays to scout around looking for similar tasks, and think about using the same coding pattern. It is not uncommon to recode a given graph node dispatch function several times during performance optimization.
Packet tracer¶
Vlib includes a frame element [packet] trace facility, with a simple vlib cli interface. The cli is straightforward: “trace add input-node-name count”.
To trace 100 packets on a typical x86_64 system running the dpdk plugin: “trace add dpdk-input 100”. When using the packet generator: “trace add pg-input 100”
Each graph node has the opportunity to capture its own trace data. It is almost always a good idea to do so. The trace capture APIs are simple.
The packet capture APIs snapshoot binary data, to minimize processing at capture time. Each participating graph node initialization provides a vppinfra format-style user function to pretty-print data when required by the VLIB “show trace” command.
Set the VLIB node registration “.format_trace” member to the name of the per-graph node format function.
Here’s a simple example:
u8 * my_node_format_trace (u8 * s, va_list * args)
{
vlib_main_t * vm = va_arg (*args, vlib_main_t *);
vlib_node_t * node = va_arg (*args, vlib_node_t *);
my_node_trace_t * t = va_arg (*args, my_trace_t *);
s = format (s, "My trace data was: %d", t-><whatever>);
return s;
}
The trace framework hands the per-node format function the data it captured as the packet whizzed by. The format function pretty-prints the data as desired.